Сравнение Node.js с JavaScript в браузере
Если вы писали на JavaScript, который работает в браузере и хотите лучше понять серверную часть, во многих статьях вам будет сказано, что Node JavaScript — отличный способ написания серверного кода и вы можете получить преимущество из вашего опыта работы с JavaScript.
Я согласен с ними, но при переходе на Node.js возникает множество проблем, даже если у вас есть опыт написания клиентского JavaScript. В этой статье предполагается, что у вас установлен Node и вы хотите использовать его для создания фронтэнд приложений, но хотите написать свои собственные API и инструменты с помощью Node.
Объяснение Node и npm для начинающих вы можете найти в статье Джейми Коркхилла
Начало работы с Nodeв Smashing Magazine.
Асинхронный JavaScript
Нам не нужно писать много асинхронного кода в браузере. Чаще всего асинхронный код в браузере используется для получения данных из API с помощью fetch (или XMLHttpRequest, если вы приверженец старой школы). Другие варианты использования асинхронного кода могут включать использование setInterval, setTimeout, или реагирование на события пользовательского ввода, но мы можем довольно далеко продвинутся в написании пользовательского интерфейса javaScript, не будучи гениями асинхронного JavaScript.
Если вы используете Node, вы почти всегда будете писать асинхронный код. С самого начала Node был создан для использования однопоточного цикла обработки событий с использованием асинхронных обратных вызовов (callbacks). В 2011 команда Node написала в блоге о том, как Node.js продвигает асинхронный стиль кодирования с нуля
. В докладе Райана Даля, анонсирующем Node.js в 2009 году, он говорит о преимуществах производительность за счёт удвоения асинхронного JavaScript.
Асинхронный стиль одна из причин, по которой Node завоевал популярность по сравнению с другими попытками серверной реализации JavaScript, такими как серверы приложений Netscape или Narwhal. Однако принуждение к написанию асинхронного JavaScript может вызвать трения, если вы к этому не готовы.
Настройка примера
Допустим, мы пишем приложение-викторину. Мы собираемся позволить пользователям создавать викторины из вопросов с несколькими вариантами ответов, чтобы проверить знания своих друзей. Вы можете найти более полную версию того, что мы создадим, в этом репозитории GitHub. Вы также можете клонировать весь фронтэнд и бэкэнд, чтобы увидеть, как они сочетаются друг с другом или можете посмотреть на этот CodeSandbox (запустите npm run start) и получите представление о том, что мы делаем.
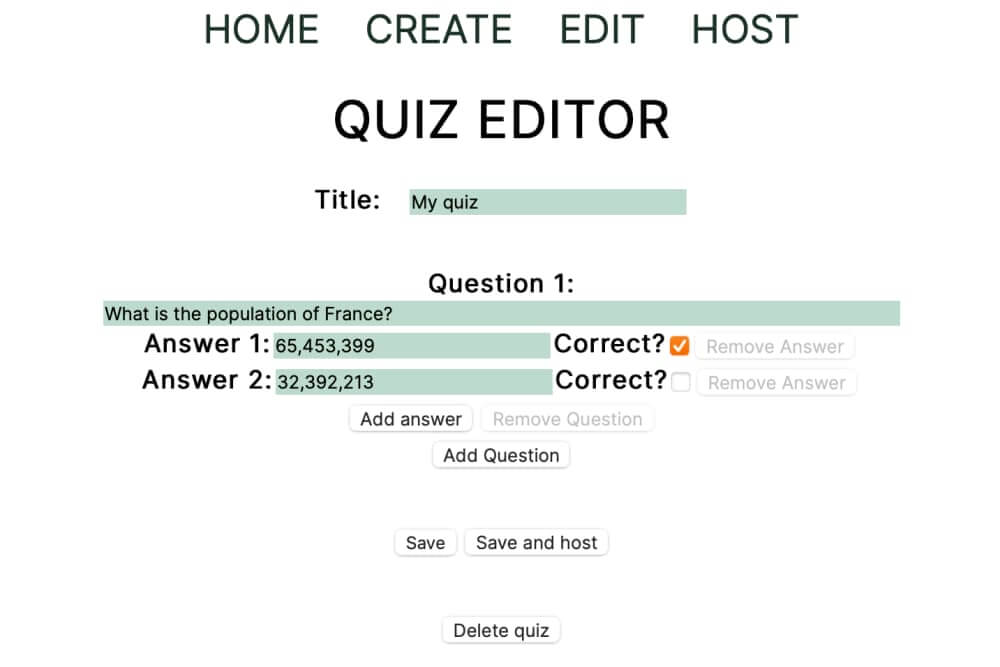
Тесты в нашем приложении будут состоять из набора вопросов, и каждый из этих вопросов будет иметь несколько ответов на выбор, причём только один ответ будет правильным.
Мы можем хранить эти данные в базе данных SQLite. Наша база данных будет содержать:
Таблица для викторин с двумя столбцами:
Идентификатор, целочисленное значение
Название викторины, текст
Таблица для вопросов с тремя колонками:
Идентификатор, целочисленное значение
Текст вопроса, текст
Целочисленное значение идентификатора викторины к которой относится вопрос
Таблица для ответов с четырьмя колонками:
Идентификатор, целочисленное значение
Текст ответа, текст
Правильный ответ или нет,
Целочисленное значение идентификатора вопроса к которому относится ответ
В SQLite нет логического типа данных, поэтому мы можем определить, является ли ответ правильным в виде целого числа, где 0 это false, а 1 это true.
Во-первых, нам нужно инициализировать npm и установить пакет sqlite3из командной строки:
npm init -y
npm install sqlite3Это создаст файл package.json. Давайте отредактируем его, добавив:
"type":"module"На верхнем уровне JSON объекта. Это позволит нам использовать современный синтаксис модуля ES6. Теперь мы можем создать скрипт для настройки таблиц. Назовём его migrate.js.
// migrate.js
import sqlite3 from "sqlite3";
let db = new sqlite3.Database("quiz.db");
db.serialize(function () {
// Setting up our tables:
db.run("CREATE TABLE quiz (quizid INTEGER PRIMARY KEY, title TEXT)");
db.run("CREATE TABLE question (questionid INTEGER PRIMARY KEY, body TEXT, questionquiz INTEGER, FOREIGN KEY(questionquiz) REFERENCES quiz(quizid))");
db.run("CREATE TABLE answer (answerid INTEGER PRIMARY KEY, body TEXT, iscorrect INTEGER, answerquestion INTEGER, FOREIGN KEY(answerquestion) REFERENCES question(questionid))");
// Create a quiz with an id of 0 and a title "my quiz"
db.run("INSERT INTO quiz VALUES(0,\"my quiz\")");
// Create a question with an id of 0, a question body
// and a link to the quiz using the id 0
db.run("INSERT INTO question VALUES(0,\"What is the capital of France?\", 0)");
// Create four answers with unique ids, answer bodies, an integer for whether
// they're correct or not, and a link to the first question using the id 0
db.run("INSERT INTO answer VALUES(0,\"Madrid\",0, 0)");
db.run("INSERT INTO answer VALUES(1,\"Paris\",1, 0)");
db.run("INSERT INTO answer VALUES(2,\"London\",0, 0)");
db.run("INSERT INTO answer VALUES(3,\"Amsterdam\",0, 0)");
});
db.close();Я не буду подробно объяснять этот код, но он создаёт таблицы необходимые для хранения наших данных. Он так же создаёт викторину, вопрос и четыре ответа, и сохраняет эти данные в файле quiz.db. После сохранения этого файла мы можем запустить наш скрипт из командной строки с помощью следующей команды:
node migrate.jsПри желании вы можете открыть файл базы данных с помощью такого инструмента, как DB Browser for SQLite, что бы убедиться, были ли созданы данные.
Изменение способа написания JavaScript
Давайте напишем код для запроса созданных нами данных.
Создайте новый файл и назовите его index.js. Чтобы получить доступ к нашей базе данных, мы импортируем sqlite3, создаём новый экземпляр sqlite3.Database и передаём ему путь к файлу базы данных в качестве аргумента. Для этого объекта базы данных мы вызовем функцию get, передав SQL строку для выбора нашей викторины и обратный вызов/(callback), который выведет в консоль наш результат.
// index.js
import sqlite3 from "sqlite3";
let db = new sqlite3.Database("quiz.db");
db.get(`SELECT * FROM quiz WHERE quizid = 0`, (err, row) => {
if (err) {
console.error(err.message);
}
console.log(row);
db.close();
});Запустив это приложение мы увидим в консоли { quizid: 0, title: 'my quiz' }.
Как не надо использовать обратные вызовы
Давайте завернём этот код в функцию, в которую мы можем передать идентификатор викторины в качестве аргумента; мы хотим получить доступ к любой викторине по её идентификатору. Эта функция возвращает объект строки базы данных, который мы получаем из базы данных.
Здесь мы начинаем сталкиваться с проблемами. Мы не можем просто вернуть объект внутри обратного вызова, который мы передаём в db, и уйти. Это не изменит того, что возвращает наша внешняя функция. Вместо этого нужно подумать, что мы можем создать переменную (назовём ей result) во внешней функции и переназначить её в обратном вызове. Вот как мы можем это реализовать:
// index.js
// Be warned! This code contains BUGS
import sqlite3 from "sqlite3";
function getQuiz(id) {
let db = new sqlite3.Database("quiz.db");
let result;
db.get(`SELECT * FROM quiz WHERE quizid = ?`, [id], (err, row) => {
if (err) {
return console.error(err.message);
}
db.close();
result = row;
});
return result;
}
console.log(getQuiz(0));Если вы запустите этот код, в консоль будет выведено undefined! Что случилось?
Мы столкнулись с несоответствием между ожидаемым выполнением JavaScript(сверху вниз) и тем, как выполняются асинхронные обратные вызовы. Функция getQuiz в приведённом выше примере работает следующим образом:
Мы объявляем переменную
resultс помощьюlet result;. Мы ничего не присваивали этой переменной, поэтому её значениеundefined.Мы вызываем функцию
db.get(). Передаём её строку SQL, идентификатор и обратный вызов. Но наш обратный вызов ещё не запускается! Вместо этого пакетSQLiteзапускает в фоновом режиме задачу для чтения из файлаquiz.db. Чтение из файловой системы занимает относительно много времени, поэтому этот API позволяет нашему коду продолжить исполнение, пока Node.js читает с диска в фоновом режиме.Наша функция возвращает
result. Поскольку наш обратный вызов ещё не запущен, результат все ещёundefined.SQLite заканчивает чтение из файловой системы и запускает переданный нами обратный вызов, закрывая базу данных и присваивая
rowпеременнойresult. Присвоение этой переменной значения не имеет, так как функция уже вернула значениеresult.
Передача обратных вызовов
Как это исправить? До 2015 года это можно было исправить с помощью обратных вызовов. Вместо того чтобы передавать только id викторины в нашу функцию, мы передаём id и обратный вызов, который получает объект row в качестве аргумента.
Вот как это выглядит:
// index.js
import sqlite3 from "sqlite3";
function getQuiz(id, callback) {
let db = new sqlite3.Database("quiz.db");
db.get(`SELECT * FROM quiz WHERE quizid = ?`, [id], (err, row) => {
if (err) {
console.error(err.message);
}
else {
callback(row);
}
db.close();
});
}
getQuiz(0,(quiz)=>{
console.log(quiz);
});Вот и всё. Небольшое изменение нашего кода приводит к том, что console.log выполняется после завершение запроса.
Ад обратных вызовов
Но что, если нам нужно сделать несколько последовательных асинхронных вызовов? Например, что если бы мы пытались выяснить, к какой викторине относится ответ, и у нас был бы только id ответа.
Во-первых, я собираюсь преобразовать getQuiz в более общую функцию, что бы мы могли передавать в запрос таблицу и столбец, так же как и идентификатор:
К сожалению мы не можем использовать (более безопасные) параметры SQL для параметризации имени таблицы, поэтому вместо этого мы переключимся на использование шаблонной строки/литерала. В коде на продакшене вам нужно будет отчистить это строку, что бы предотвратить SQL-инъекцию.
function get(params, callback) {
// На продакшене вам нужно будет отчистить это строку, что бы предотвратить SQL-инъекцию
const { table, column, value } = params;
let db = new sqlite3.Database("quiz.db");
db.get(`SELECT * FROM ${table} WHERE ${column} = ${value}`, (err, row) => {
callback(err, row);
db.close();
});
}Следующая проблема заключается в том, что может возникнуть ошибка чтения из базы данных. Наш код должен знать, была ли ошибка в запросе к базе данных; в противном случае он не должен продолжать запрашивать данные. Мы будем использовать соглашение Node.js о передаче объекта ошибки в качестве первого аргумента нашего обратного вызова. Затем мы можем проверить, была ли ошибка, прежде чем идти дальше.
Давайте возьмём наш ответ с id равным 2 и проверим, к какой викторине он относится. Вот как мы можем это сделать с помощью обратных вызовов:
// index.js
import sqlite3 from "sqlite3";
function get(params, callback) {
// На продакшене вам нужно будет отчистить это строку, что бы предотвратить SQL-инъекцию
const { table, column, value } = params;
let db = new sqlite3.Database("quiz.db");
db.get(`SELECT * FROM ${table} WHERE ${column} = ${value}`, (err, row) => {
callback(err, row);
db.close();
});
}
get({ table: "answer", column: "answerid", value: 2 }, (err, answer) => {
if (err) {
console.log(err);
} else {
get(
{ table: "question", column: "questionid", value: answer.answerquestion },
(err, question) => {
if (err) {
console.log(err);
} else {
get(
{ table: "quiz", column: "quizid", value: question.questionquiz },
(err, quiz) => {
if (err) {
console.log(err);
} else {
// Это викторина, которой принадлежит наш ответ
console.log(quiz);
}
}
);
}
}
);
}
});Вау, сколько вложений! Каждый раз, когда мы получаем ответ из базы данных, мы должны добавить два уровня вложенности — один для проверки на наличие ошибки и один для следующего обратного вызова. По мере того как мы связываем всё больше и больше асинхронных вызовов, наш код становится всё глубже и глубже.
Мы могли бы частично предотвратить это, используя именованные функции вместо анонимных, что уменьшило бы вложенность, но сделало бы наш код менее кратким. Мы так же должны придумать имена для всех этих промежуточных функций. К счастью, в 2015 году в Node появились промисы, помогающие с подобными асинхронными вызовами.
Промисы
Обёртывание асинхронных задач промисами позволяет избежать вложенности из предыдущего примера. Вместо того чтобы получать всё более и более глубокие вложенные вызовы, мы можем передать обратный вызов в функцию Promise then.
Во-первых, давайте изменим нашу функцию get, чтобы она обрабатывала запрос к базе данных с Promise:
// index.js
import sqlite3 from "sqlite3";
function get(params) {
// На продакшене вам нужно будет отчистить это строку, что бы предотвратить SQL-инъекцию
const { table, column, value } = params;
let db = new sqlite3.Database("quiz.db");
return new Promise(function (resolve, reject) {
db.get(`SELECT * FROM ${table} WHERE ${column} = ${value}`, (err, row) => {
if (err) {
return reject(err);
}
db.close();
resolve(row);
});
});
}Теперь наш код поиска викторины, часть которой является ответ, может выглядеть так:
get({ table: "answer", column: "answerid", value: 2 })
.then((answer) => {
return get({
table: "question",
column: "questionid",
value: answer.answerquestion,
});
})
.then((question) => {
return get({
table: "quiz",
column: "quizid",
value: question.questionquiz,
});
})
.then((quiz) => {
console.log(quiz);
})
.catch((error) => {
console.log(error);
}
);Это гораздо более удобный способ обработки нашего асинхронного кода. И нам больше не нужно индивидуально обрабатывать ошибки для каждого вызова, мы можем использовать функцию catch для обработки любых ошибок, которые происходят в нашей цепочке функций.
Нам всё ещё нужно писать много обратных вызовов, чтобы это заработало. К счастью, есть новый API, который поможет! Когда вышел Node 7.6.0, он обновил свой движок JavaScript до V8 5.5, который включил возможность писать функции ES2017 async/await.
Async/Await
С помощью async/await мы можем писать наш асинхронный код почти так же, как мы пишем синхронный код. У Сары Драснер есть отличная статья, объясняющая async/await.
Когда у вас есть функция возвращающая Promise, вы можете использовать ключевое слово await перед её вызовом, и это предотвратит переход вашего кода на следующую строку, пока Promise не будет выполнен. Поскольку мы уже переработали функцию get() для возврата промиса, нам нужно только изменить наш пользовательский код:
async function printQuizFromAnswer() {
const answer = await get({ table: "answer", column: "answerid", value: 2 });
const question = await get({
table: "question",
column: "questionid",
value: answer.answerquestion,
});
const quiz = await get({
table: "quiz",
column: "quizid",
value: question.questionquiz,
});
console.log(quiz);
}
printQuizFromAnswer();Это выглядит более привычно для кода, который мы привыкли читать. Буквально в этом году Node выпустила await верхнего уровня. Это означает, что мы можем сделать этот пример ещё более кратким, удалив функцию printQuizFromAnswer() обернувшую вызов функции get().
Теперь у нас есть лаконичный код, который будет последовательно выполнять каждую из этих асинхронных задач. Мы так же могли бы одновременно запускать другие асинхронные функции (такие, как чтение из файлов или ответы на HTTP-запросы), пока мы ждём выполнение этого кода. Это преимущество всего асинхронного стиля.
Поскольку в Node так много асинхронных задач, таких как чтение из сети или доступ к базе данных или файловой системе. Особенно важно понимать эти концепции. У них так же есть небольшая кривая обучения.
Использование всего потенциала SQL
Есть ещё лучший способ! Вместо того, что бы беспокоиться об этих асинхронных вызовах для получения каждой части данных, мы могли бы использовать SQL для получения всех необходимых данных в одном большом запросе. Мы можем сделать это с помощью SQL-запроса JOIN:
// index.js
import sqlite3 from "sqlite3";
function quizFromAnswer(answerid, callback) {
let db = new sqlite3.Database("quiz.db");
db.get(
`SELECT *,a.body AS answerbody, ques.body AS questionbody FROM answer a
INNER JOIN question ques ON a.answerquestion=ques.questionid
INNER JOIN quiz quiz ON ques.questionquiz = quiz.quizid
WHERE a.answerid = ?;`,
[answerid],
(err, row) => {
if (err) {
console.log(err);
}
callback(err, row);
db.close();
}
);
}
quizFromAnswer(2, (e, r) => {
console.log(r);
});Это вернёт нам все необходимы данные о нашем ответе, вопросе и викторине в одном большом объекте. Мы также переименовали каждый столбец body для ответов и вопросов в answerbody и questionbody, чтобы различать их. Как видите, добавление большого количества логики на уровень базы данных может упростить на JavaScript (а также, возможно, повысить производительность).
Если вы используете реляционную базу данных, такую как SQLite, вам нужно изучать совершенно другой язык с множеством разных функций, которые могут сэкономить время, усилия и повысить производительность. Это добавляет ещё больше вещей, которые нужно изучить для написания на Node.
Node API и соглашения
Есть множество новых Node API, которые нужно изучить при переходе с кода браузера на Node.js.
Любые подключения к базе данных и/или чтению файловой системы используют API, которых нет в браузере (пока). У нас есть новый API для настройки HTTPS-серверов. Мы можем проверять операционную систему используя модуль OS, и мы можем шифровать данные с помощью модуля Crypto. Кроме того, чтобы сделать HTTP-запрос от узла (что мы делаем в браузере всё время), у нас нет функции fetch или XMLHttpRequest. Вместо этого нам нужно импортировать модуль https. Однако недавний запрос на добавление в репозитории node.js показывает, что fetch в node уже в пути! Всё ещё существует множество несоответствий между браузерами и Node API. Это одна из проблем, которую Deno намерен решить.
Нам так же необходимо знать о соглашениях Node, в том числе о package.json файле. Большинство фронтэнд разработчиков хорошо знакомы с ним, если использовали инструменты для сборки. Если вы хотите опубликовать библиотеку, часть, к которой вы возможно не привыкли, — это свойство main в файле package.json. Это свойство содержит путь указывающий на точку входа в библиотеку.
Существуют также соглашения, такие как первый аргумент — ошибка в обратном вызове: когда Node API принимает обратный вызов, который принимает ошибку в качестве первого аргумента и результат в качестве второго аргумента. Вы могли видеть это ранее в коде нашей базы данных и ниже в функции readFile.
import fs from 'fs';
fs.readFile('myfile.txt', 'utf8' , (err, data) => {
if (err) {
console.error(err)
return
}
console.log(data)
})Различные типы модулей
Ранее я небрежно посоветовал добавить "type": "module" в ваш package.json, чтобы примеры кода заработали. Когда Node был создан, в 2009 году, создателям была нужна модульная система, но в спецификации JavaScript её не было. Они придумали модули Common.js для решения этой проблемы. В 2015 году в JavaScript была введена спецификация модуля, в результате чего Node.js имел модульную систему отличную от нативных модулей JavaScript. После титанических усилий команды Node мы можем использовать эти нативные модули JavaScript в Node.
К сожалению, это означает, что многие сообщения в блогах и ресурсы будут написаны с использованием старой модульной системы. Это также означает, что многие пакеты npm не будут использовать нативные модули JavaScript, а также будут библиотеки использующие нативные JavaScript модули будут несовместимы образом!
Другие проблемы
Есть ещё несколько проблем о которых нам нужно подумать при написании Node. Если вы используете сервер Node и возникает фатальное исключение, сервер завершает работу и перестаёт отвечать на любые запросы. Это означает, что если вы завершите достаточно серьёзную ошибку на сервер Node, ваше приложение будет сломано для всех. Это отличается от клиентского JavaScript, где крайний случай вызывающий фатальную ошибку, возникает у одного пользователя за раз, и у этого пользователя есть возможность обновить страницу.
Безопасность — это то, о чём мы должны беспокоиться во внешнем интерфейсе с межсайтовым скриптами и подделкой межсайтовых запросов. Но внутренний сервер имеет более широкую поверхность для атак с уязвимостями, включая атаки методом перебора и SQL-инъекцию. Если вы храните и получаете доступ к информации людей с помощью Node, то вы несёте большую ответственность за обеспечение безопасности их данных.
Заключение
Node — отличный способ использовать свои навыки JavaScript для создания серверов и инструментов командной строки. JavaScript — это удобный язык на котором мы привыкли писать. А асинхронный характер Node означает, что вы можете быстро справляться с одновременными задачами. Но есть много новых вещей, которые нужно узнать, когда вы начнёте. Вот ресурсы, которые я рекомендую прочитать, прежде чем прыгать в Node JS:
- Asynchronous JavaScript (MDN)
- Understanding Async Await (Sarah Drasner)
- Introduction to Node.js (Node.js Documentation)
- Get Started With Node (Jamie Corkhill)
- Original Node.js presentation (Ryan Dahl)
- Native JavaScript modules (Node.js Documentation)
И если вы планируете хранить данные в базе данных SQL, прочитайте Основы SQL