Всё что нужно знать о HTTP протоколе
HTTP — это протокол, который должен знать каждый веб-разработчик, поскольку он поддерживает всю сеть. Знание HTTP, безусловно, может помочь в разработке более качественных приложений.
В этой статье я расскажу, что такое HTTP, как он появился, где находится сегодня и как мы к этому пришли.
Что такое HTTP
Прежде всего, что такое HTTP? HTTP — это протокол связи прикладного уровня на основе TCP/IP, который стандартизирует взаимодействие клиентов и серверов друг с другом. Он определяет, как контент запрашивается и передаётся через Интернет. Под протоколом прикладного уровня я подразумеваю просто уровень абстракции, который стандартизирует взаимодействие хостов (клиентов и серверов). Сам HTTP зависит от TCP/IP для получения запросов и ответов между клиентом и сервером. По умолчанию используется TCP-порт 80, но можно использовать и другие порты. Однако HTTPS использует порт 443.
HTTP 0.9 — Однострочный (1991)
Первой задокументированной версией HTTP была HTTP/0.9, которая была предложена в 1991 году. Это был самый простой протокол; имеющий единственный метод называемый GET. Если бы клиенту нужно было получить доступ к какой-либо веб-странице на сервере, он сделал бы простой запрос, как показано ниже.
GET /index.htmlОтвет от сервера выглядел бы следующим образом.
(response body)
(connection closed)То есть сервер получит запрос, ответит HTML-кодом в ответ, и как только контент будет передан, соединение будет закрыто. Было:
- Без заголовков
GETединственный разрешённый метод- Ответ должен быть HTML
Как видите, протокол действительно был не чем иным, как ступенькой к тому, что должно было произойти.
HTTP/1.0 - 1996
В 1996 была разработана следующая версия HTTP, то есть HTTP/1.0, которая значительно улучшилась по сравнению с исходной версией.
В отличие от HTTP/0.9, который был разработан только для HTML ответов, HTTP/1.0 теперь может работать с другими форматами ответов, т.е. с изображениями, видеофайлами, обычным текстом или любым другим типом контента. Добавлено больше методов (например, POST и HEAD), измены форматы запроса/ответа, добавлены HTTP заголовки как к запросу, так и к ответам. Добавлены коды состояния для идентификации ответа, введена поддержка набора символов, многокомпонентные типы, авторизация, кэширование, кодирование контента и многое другое.
Вот так может выглядеть пример запроса и ответа HTTP/1.0:
GET / HTTP/1.0
Host: cs.fyi
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5)
Accept: */*Как видите, вместе с запросом клиент также отправил свою личную информацию, требуемый тип ответа и т.д. В то время как в HTTP/0.9 клиент никогда не мог отправить такую информацию, потому что не было заголовков.
Пример ответа на приведённый выше запрос мог выглядеть следующим образом.
HTTP/1.0 200 OK
Content-Type: text/plain
Content-Length: 137582
Expires: Thu, 05 Dec 1997 16:00:00 GMT
Last-Modified: Wed, 5 August 1996 15:55:28 GMT
Server: Apache 0.84
(response body)
(connection closed)
В самом начале ответа есть HTTP/1.0 (HTTP, за которым следует номер версии), затем идёт код состояния 200 за которым следует фраза причины (или описание кода состояния, если хотите).
В этой более новой версии заголовки запроса и ответа по-прежнему сохранялись в кодировке ASCII, но тело ответа могло быть любого типа, т.е. изображение, видео, HTML, обычный текст или любой другой тип содержимого. Итак, теперь этот сервер может отправлять клиенту контент любого типа; вскоре после введения термин гипертекст
в HTTP стал неправильным. Протокол передачи HMTP или Hypermedia мог бы иметь больше смысла, но, я думаю, что мы застряли с этим именем на всю жизнь.
Одним из основных недостатков HTTP/1.0 было то, что вы не могли иметь несколько запросов на одно соединение. То есть всякий раз, когда клиенту потребуется что-то от сервера, ему придётся открыть новое TCP-соединение, и после того, как этот единственный запрос будет выполнен, соединение будет закрыто. И для любого последующего запроса должно быть новое соединение. Почему это плохо? Что ж, давайте предположим, что вы посещаете веб-страницу с 10 изображениями, 5 таблицами стилей и 5 файлами JavaScript, всего 20 элементов, которые необходимо получить при выполнении запроса на эту веб-страницу. Поскольку сервер закрывает соединение, как только запрос будет выполнен, будет серия из 20 отдельных соединений, где каждый из элементов будет обслуживаться один за другим на своих отдельных соединениях. Такое большое количество подключений приводит к серьёзному снижению производительности, поскольку требование нового TCP-подключения приводит к значительному снижению производительности из-за трёхэтапного рукопожатия (three-way handshake), за которым следует медленный старт.
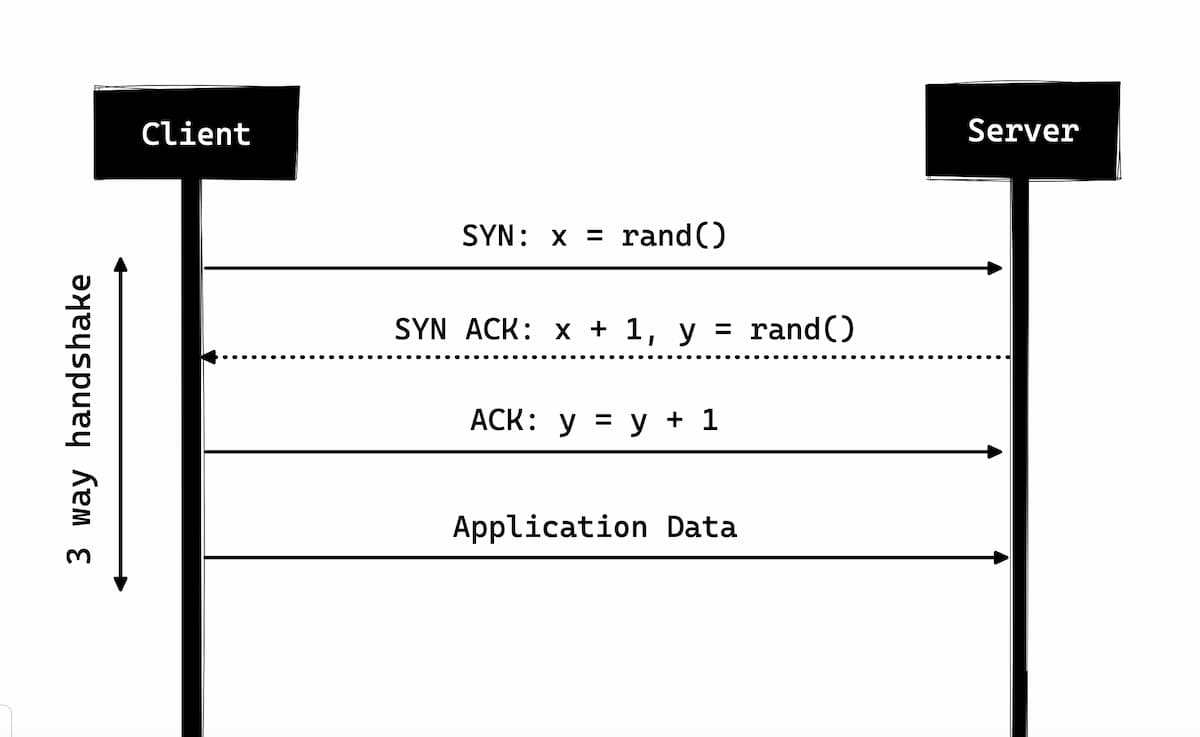
Трёхэтапное рукопожатие
Трёхэтапное рукопожатие в простой форме заключается в том, что все TCP-соединения начинаются с трёхэтапного рукопожатия, в котором клиент и сервер совместно используют серию пакетов, прежде чем начать совместно использовать данные приложения.
- SYN — Клиент выбирает случайное число, скажем,
x, и отправляет его на сервер. - SYN ACK — Сервер подтверждает запрос, отправляя пакет
ACKобратно клиенту, который состоит из случайного числа, скажем,y, полученного сервером, и числаx+1, гдеx— это число отправленное клиентом. - ACK — Клиент увеличивает число
y, полученное от сервера, и отправляет обратно пакетACKс числомy+1.
После завершения трёхэтапного рукопожатия может начаться обмен данными между клиентом и сервером. Следует отметить, что клиент может начать отправку данных приложения, как только он отправит последний пакет ACK, но серверу всё равно придётся ждать получения пакета ACK, чтобы выполнить запрос.
Однако некоторые реализации HTTP/1.0 пытались решить эту проблему, вводя новый заголовок Connection: keep-alive, который должен был сказать серверу: Эй, сервер, не закрывай это соединение, оно мне снова нужно
. Тем не менее это было не так широко поддержано, и проблема всё ещё сохранялась.
Помимо отсутствия соединения, HTTP также является протоколом без сохранения состояния, т.е. сервер не хранит информацию о клиенте, поэтому каждый из запросов должен иметь информацию, необходимую серверу для выполнения запроса самостоятельно без какой-либо связи с каким-либо старым запросом. И это подливает масла в огонь, т.е. помимо большого количества соединений, которые должен открыть клиент, ему также приходится отправлять некоторые избыточные данные, что приводит к увеличению использования полосы пропускания.
HTTP/1.1 - 1997
Всего через три года после выхода HTTP/1.0, в 1997 году была выпущена HTTP/1.1 в которой произошло много улучшений по сравнению с предшественником. Основные улучшения по сравнению с HTTP/1.0 включают:
Новые HTTP методы — Были добавлены
PUT,PATCH,OPTIONSиDELETE.Идентификация имени хоста — В HTTP/1.0 не требовалась, но в HTTP/1.1 стала обязательной.
Постоянные соединения — Как обсуждалось выше, в HTTP/1.0 был только один запрос на соединение, и соединение закрывалось, как только запрос был выполнен, что приводило к резкому снижению производительности и проблемами с задержкой. HTTP/1.1 представил постоянные соединения, т.е. соединения не закрывались по умолчанию и оставались открытыми, что позволяло выполнить несколько последовательных запросов. Чтобы закрыть соединение, в запросе должен быть заголовок
Connection: close. Клиенты обычно отправляют этот заголовок в последнем запросе, чтобы безопасно закрыть соединение.Конвейерная обработка — Также была добавлена поддержка конвейерной обработки, при которой клиент мог отправлять несколько запросов на сервер, не дожидаясь ответа от сервера по тому же соединения, и сервер должен был отправлять ответ в той же последовательности, в которой были получены запросы. Но как клиент узнает, что это точка, где завершается загрузка первого ответа и начинается контент для следующего ответа, спросите вы! Ну, чтобы решить эту проблему, должен присутствовать заголовок
Content-Length, который клиенты могут использовать для определения, где заканчивается ответ, и он может начать ждать следующий ответ.Следует отметить, что для того, чтобы извлечь выгоду из постоянных соединений или конвейерной обработки, заголовок
Content-Lengthдолжен быть доступен в ответе, потому что это позволит клиенту узнать, когда передача завершится, и он может отправить следующий запрос (обычным последовательным способом) или начать ждать следующего ответа (при конвейерной обработке). Но с этим подходом всё ещё была проблема. То есть, что, если данные динамические и сервера не может определить длину содержимого заранее? Ну, в таком случае, вы действительно не можете извлечь выгоду из постоянных соединений, не так ли? Чтобы решить эту проблему, в HTTP/1.1 введено кодирование по частям. В таких случаях сервер может опуститьContent-Lengthв пользу фрагментированного кодирования (подробнее об этом чуть позже). Однако, если ни один из них не доступен, то соединение должно быть закрыто в конце запроса.Передача по частям — В случае динамического контента, когда сервер не может определить
Content-Lengthв начале передачи, он может начать отправлять контент по частям (фрагмент за фрагментом) и добавлятьContent-Lengthдля каждого фрагмента при его отправке. И когда все фрагменты отправлены, то есть вся передача завершена, он отправляет пустой фрагмент, то есть тот, у которогоContent-Lengthустановлен на ноль, чтобы идентифицировать клиента, передача которого завершена. Чтобы уведомить клиента о фрагментированной передаче, сервер включает заголовокTransfer-Encoding: chunked.В отличие от HTTP/1.0, который имел только обычную аутентификацию, HTTP/1.1 включал дайджест и прокси-аутентификацию.
Кэширование
Диапазоны байтов
Наборы символов/кодировки
Согласование языка
Cookie-файлы клиента
Расширенная поддержка сжатия
Новые коды состояния
… и многое другое
Не буду подробно останавливаться на всех возможностях HTTP/1.1 в этой статье, так как это отдельная тема, и вы можете найти многое о ней. Один из таких документов, которые я бы порекомендовал вам почитать, — Key differences between HTTP/1.0 and HTTP/1.1
, а также вот ссылка на оригинальный RFC для тех кто хочет знать всё.
HTTP/1.1 был представлен в 1999 году и уже много лет является стандартом. Хотя он значительно улучшился по сравнению со своим предшественником; Интернет меняется каждый день, и он начал показывать свой возраст. Загрузка веб-страниц в наши дни стребует больше ресурсов, чем когда-либо. Простая веб-страница в наши дни должна открывать более 30 подключений. Что ж, HTTP/1.1 имеет постоянные соединения, тогда зачем так много соединений? Причина в том, что в HTTP/1.1 может быть только одно активное соединения в любой момент времени. HTTP/1.1 попытался исправить это, внедрив конвейерную обработку, но это не решило проблему полностью из-за блокировки заголовка строки, когда медленный или тяжёлый запрос может блокировать последующие запросы, и как только запрос застревает в конвейере, ему придётся ждать выполнения следующих запросов. Чтобы преодолеть эти недостатки HTTP/1.1, разработчики начали реализовывать обходные пути, например, использование таблиц спрайтов, изображений закодированных в CSS, одиночных огромных CSS/JavaScript файлов, сегментирование домена и т.д.
SPDY - 2009
Google пошёл дальше и начал экспериментировать с альтернативными протоколами, чтобы сделать Интернет быстрее и повысить безопасность в Интернете, а также уменьшить задержку веб-страниц. В 2009 году они анонсировали SPDY.
SPDY — это торговая марка Google и это не акроним.
Было замечено, что если мы продолжаем увеличивать пропускную способность, производительность сети сначала увеличивается, но наступает момент, когда прирост производительности невелик. Но если вы сделаете то же самое с задержкой, то есть если мы будем продолжать снижать задержку, будет постоянный прирост производительности. Это была основная идея повышения производительности SPDY, уменьшение задержки для повышения производительности сети.
Для тех, кто не знает разницы, задержка — это время, необходимое для передачи данных между источником и получателем (измеряется в миллисекундах), а пропускная способность — это количество данных, передаваемых в секунду (бит в секунду).
Функции SPDY включают мультиплексирование, сжатие, приоритизацию, безопасность и т.д. Я не собираюсь вдаваться в подробности SPDY, так как вы поймёте, когда мы углубимся в суть HTTP/2 в следующем разделе, поскольку я бы сказал, что HTTP/2 в основном вдохновлён SPDY.
SPDY на самом деле не пытался заменить HTTP; это был уровень перевода через HTTP, который существовал на уровне приложения и модифицировал запрос перед его отправкой по сети. Он стал стандартом де-факто, и большинство браузеров начали его внедрять.
В 2015 году Google не хотел иметь два конкурирующих стандарта, поэтому они решили объединить его с HTTP, породив HTTP/2 и отказавшись от SPDY.
HTTP/2 - 2015
К этому моменту вы должны быть уверены, что нам понадобилась ещё одна версия протокола HTTP. HTTP/2 был разработан для передачи контента с малой задержкой. Ключевые особенности или отличия от старой версии HTTP/1.1 включают:
- Бинарные данные вместо текстовых.
- Мультиплексирование — Несколько асинхронных HTTP-запросов по одному соединению.
- Сжатие заголовков с помощью HPACK.
- Server Push — несколько ответов на один запрос.
- Приоритизация запросов.
- Безопасность.
1. Бинарный протокол
HTTP/2 имеет тенденцию решать проблему увеличенной задержки, которая существовала в HTTP/1.x, делая его бинарным протоколом. Будучи бинарным протоколом, его легче анализировать, но в отличие от HTTP/1.x, он больше не читается человеческим глазом. Основными строительными блоками HTTP/2 являются Фреймы и Потоки.
Фреймы и Потоки
Сообщения HTTP теперь состоят из одного или нескольких фреймов. Существует фрейм HEADERS для метаданных и фрейм DATA для полезной нагрузки, а также существует несколько других типов фреймов (HEADERS, DATA, RST_STREAM, SETTINGS, PRIORITY и т.д.).
Каждому запросу и ответе HTTP/2 присваивается уникальный идентификатор потока, и он делится на фреймы. Фреймы — это не что иное, как двоичные фрагменты данных. Набор фреймов называется Потоком. Каждый фрейм имеет идентификатор потока, идентифицирующий поток, которому он принадлежит, и каждый фрейм имеет общий заголовок. Кроме того, помимо уникальности идентификатора потока, стоит отметить, что любой запрос, инициированный клиентом, использует нечётные числа, а ответ сервера имеет идентификаторы потоков с чётными номерами.
Помимо HEADERS и DATA, ещё один тип фрейма, который, я думаю, стоит здесь упомянуть — это RST_STREAM, представляющий собой специальный тип фрейма, использующийся для прерывания некоторого потока, т.е клиент может отправить этот фрейм, чтобы сообщить серверу, что мне больше не нужен этот поток. В HTTP/1.1 единственный способ заставить сервер прекратить отправку ответа клиенту было закрытие соединения, что приводило к увеличению задержки, поскольку для любых последовательных запросов приходилось открывать новое соединение. Находясь в HTTP/2, клиент может использовать RST_STREAM и прекратить получение определённого потока, в то время как соединение всё ещё будет открыто, и другие потоки всё ещё будут работать.
2. Мультиплексирование
Поскольку HTTP/2 является бинарным протоколом и, как я сказал выше, использует фреймы и потоки для запросов и ответов, после открытия TCP-соединения все потоки отправляются асинхронно через одно и то же соединение без открытия каких-либо дополнительных соединений. И, в свою очередь, сервер отвечает таким же асинхронным образом, т.е. ответ не имеет порядка, и клиент использует назначенный идентификатор потока для идентификации потока, которому принадлежит конкретный пакет. Это также решило проблему блокировки заголовка строки, существовавшую в HTTP/1.x, т.е. клиенту не придётся ждать запроса, который требует времени, а другие запросы всё ещё будут обрабатываться.
3. Сжатие заголовка
Это было часть отдельно RFC, специально предназначенного для оптимизации отправляемых заголовков. Суть в том, что когда мы постоянно обращаемся к серверу с одного и того же клиента, возникает много избыточных данных, отправляемых в заголовках снова и снова, иногда это могут быть Cookie файлы, увеличивающие размер заголовка, что приводит к уменьшению пропускной способности и повышению задержки. Чтобы преодолеть это в HTTP/2 было введено сжатие заголовков.
В отличие от запроса и ответа, заголовки не сжимаются в форматах gzip или compress и т.д., но для сжатия заголовка используется другой механизм, заключающийся в том, что литеральные значения кодируются с использованием кода Хаффмана, а таблица заголовков поддерживается клиентом и сервером и оба клиент и сервер пропускают любые повторяющиеся заголовки (например, User agent и т.д.) в последующих запросах и ссылаются на них, используя таблицу заголовков, поддерживаемую обоими.
Пока мы говорим о заголовках, позвольте мне добавить, что заголовки всё те же, что и в HTTP/1.1, за исключением некоторых псевдо заголовков, например :method, :scheme, :host и :path.
4. Server Push
Server push — ещё одна замечательная особенность HTTP/2, когда сервер зная, что клиент будет запрашивать определённый ресурс, может передать его клиенту, даже если клиент не спросит его об этом. Например, предположим, что браузер загружает веб-страницу, анализирует всю страницу, чтобы найти удалённый контент, который он должен загрузить с сервера, а затем последовательно отправляет запросы на сервер для получения этого контента.
Server push позволяет серверу уменьшить круговые обращения, отправляя данные, которые он знает, что клиент будет требовать. Как это делается, сервер отправляет специальный фрейм с именем PUSH_PROMISE, уведомляющий клиента о том, что Эй, я собираюсь отправить вам этот ресурс" Не просите меня об этом
. Фрейм PUSH_PROMISE связан с потоком, вызывавшим отправку, и содержит обещанный идентификатор потока, т.е. поток, в котором сервер отправит ресурс.
5. Приоритизация запросов
Клиент может назначить приоритет потоку, включив информацию о приоритете в фрейм HEADERS, которым открывается поток. В любое другое время клиент может отправить фрейм PRIORITY, чтобы вновь изменить приоритет потока.
Без какой-либо информации о приоритете сервер обрабатывает запросы асинхронно, то есть без какого-либо порядка. Если потоку назначен приоритет, то на основе этой информации о приоритетах сервер решает, сколько ресурсов необходимо предоставить для обработки того или иного запроса.
6. Безопасность
Было широкое обсуждение того, следует ли сделать безопасность (через TLS) обязательной для HTTP/2 или нет. В итоге было решено сделать её не обязательной. Однако большинство поставщиков, заявили, что они будут поддерживать HTTP/2 только при использовании через TLS. Таким образом, хотя HTTP/2 не требует шифрования по спецификациям, но в любом случае оно стало обязательным по умолчанию. Учитывая это, HTTP/2 при реализации через TLS накладывает некоторые требования, т.е должен использоваться TLS версии 1.2 или выше, должен быть определённый уровень минимальных размеров ключей, требуются эфемерные ключи и т.д.
Подробнее о TLS можно знать в статье: Основы TLS